




核心卖点:
AI人声建模,快速得到专业听感
本地处理引擎,安心高效不依赖网络
多模型与自定义声线,灵活打造多种风格
内建专业效果链,一站式优化与润色
支持导入中文素材
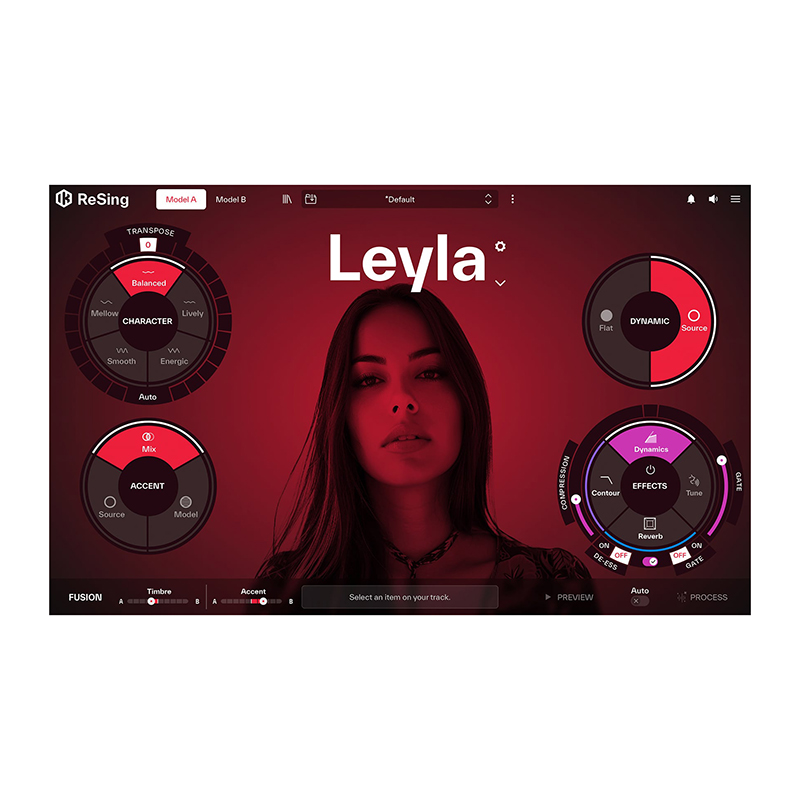
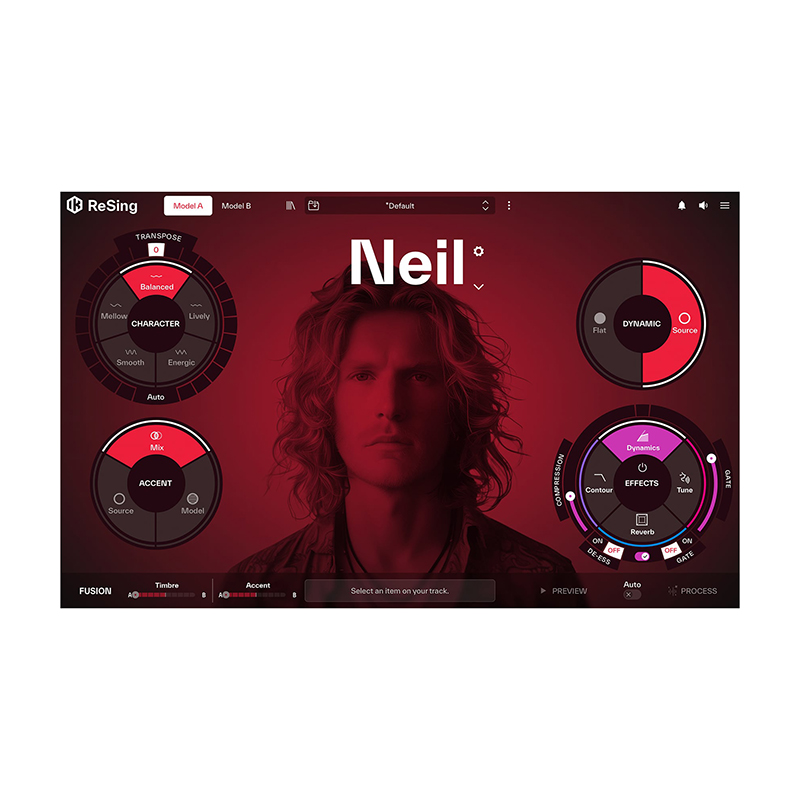
支持处理中文朗诵、演唱素材,并可自定义口音:Source原素材口音,Model模型口音,Mix混合口音。
将随手录唱转换成专业歌声
采用先进AI技术,将手机录音或草稿唱段,一键转换为专业歌手的声音,轻松获得接近唱片成品的声音表现
本地运算,可独立运行,安全高效
无需上传素材到网络,支持独立App和插件(AU/VST3/AAX)
工作流程稳定快速,同时有利于保护隐私
声音可塑性高,适配多种风格
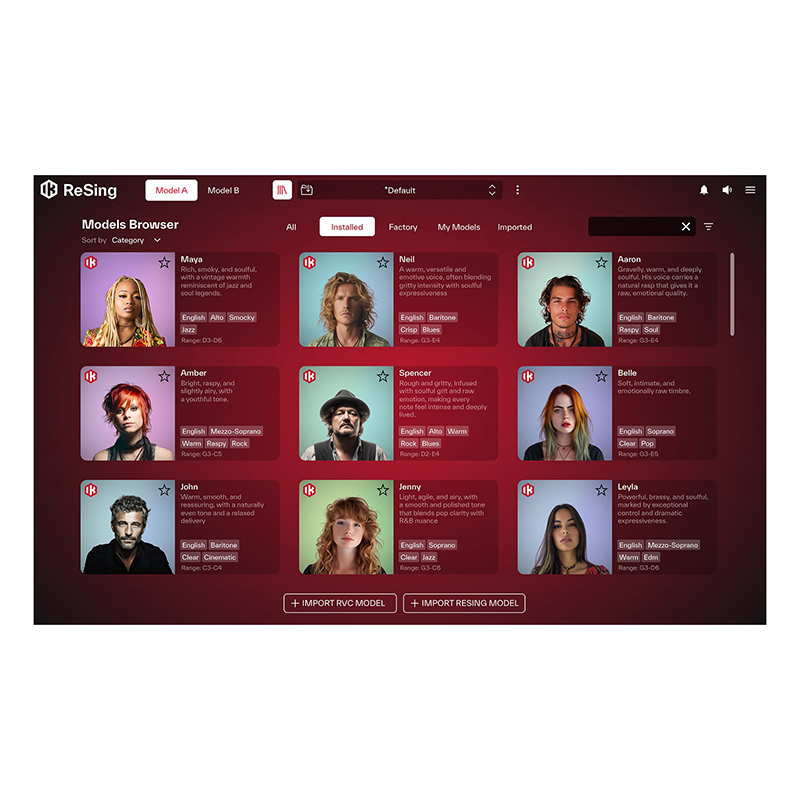
内置多种人声与乐器模型,可自由调节音色特性
支持RVC*模型导入与用户自建模,拥有更多变化与选择
*RVC (基于检索的语音转换)是领先的免费人工智能技术,可以将一个人的声音转换成另一个人的声音,并提供数百个免费模型。
内建常用混音模块,一站式快速产出
内置压缩,混响,去齿音等专业效果器,从模型转换到声音润色一站式完成
适用场景:
快速将Demo提升为更具表现力的人声版本
录音条件有限,希望获得更专业听感
多声部创作、合唱、和声制作
游戏、广告、影视配乐需要合成或拟真人声
为虚拟歌手或角色制作音色模型
内容创作者快速产出高质量人声旁白
常见问题解答:
1.支持中文吗?
ReSing支持中文素材导入处理,包括语音和演唱,并且支持选择口音(Accent),您可以保留原素材的口音(Source)或使用模型自带的口音(Model),或将二者智能结合(Mix),模型自带口音为英语和西班牙语,更多语言类型持续更新中。
2.ReSing可以用于语音合成吗?
可以。一些特定的模型——标记为Narrator——是专门为配音、播客和旁白而设计的,它们是专门针对语音和演讲进行训练的。
3.如何自己建模?
您可以使用ReSing Modeler (App)创建自己的模型。要构建模型,您需要大约15分钟的干净音频,音频源可以是您想要建模的人声或乐器。
根据系统性能的不同,建模时间不同,在 NVIDIA RTX GPU 上可能只需 20 分钟,而在仅使用 CPU 的系统上则可能需要几天时间。
4.ReSing是否支持ARA?
ReSing 支持ARA2(音频随机访问),这项技术可与兼容的 DAW 无缝集成,让您无需手动传输文件即可直接在音轨上处理音频。
目前,ReSing 支持以下 DAW 的 ARA 模式:
Cubase 12.0 或更高版本
Logic Pro X 10.4 或更高版本(仅限 Intel 架构)
Studio One 4.0 或更高版本
Nuendo 11.0 或更高版本
Reaper 5.97 或更高版本




关注公众号
了解最新产品资讯
Copyright © 2018 艺佰联腾电子科技有限公司 版权所有
