如果你最近刷到“AI 翻唱”、“AI 声音克隆”、“AI 让你唱歌像周杰伦/花泽香菜”等关键词,那你大概率也已经听说过 IK ReSing 了。
它不是玩具,它是 IK Multimedia 官方出品的专业 AI 歌声与配音工具。
它能做什么?一句话概括:
你唱,我换;你说,我配;你给素材,我造个新声音。
而且所有处理都在你电脑本地做,不用上传音频到云端。
这带来的好处是:快、隐私、安全,不怕泄露。
下面这篇文章,我们将用直观的语言带你看懂——
ReSing 到底能做什么?怎么用?效果能做到多“离谱”?以及一些常见问题与解答。
准备好了,我们开始。
ReSing能做什么
1. 把你的歌声换成另一种嗓音(Re-singing)
你可以把 ReSing 想象成一个“懂音乐的换声魔法师”:
我唱一句《晴天》,声音普通;
交给 ReSing,它能让这句变成“更干净的专业声线”,甚至换成另一种风格。
它不是把旋律重唱一遍,而是你的唱法 + 别人的音色。
2. 把配音换成另一种声音(Redubbing)
比如你录了旁白:“欢迎来到我的频道。”
ReSing 能把这句话换成成熟男声、少年声、温柔女声……甚至花栗鼠或机器人都可以。
3.自己训练一个独一无二的 AI 声音模型(Modeler)
你想把自己、朋友、配音演员的声音变成“可复用的模型”?
ReSing 自带建模器,只需要:
约 15 分钟干净的录音素材就能训练一个模型。
之后你就拥有了一位 AI 版“你自己”。
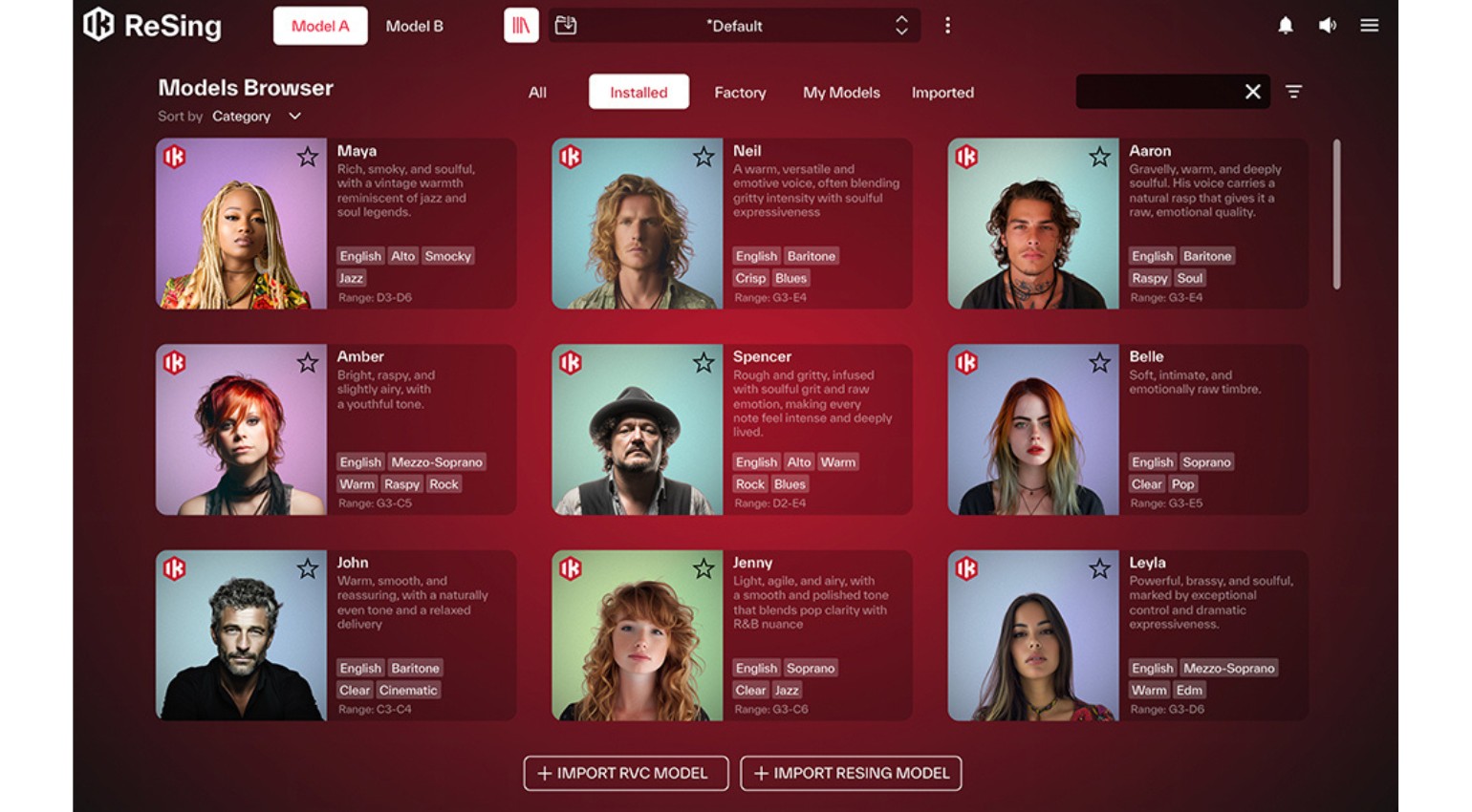
ReSing使用教程
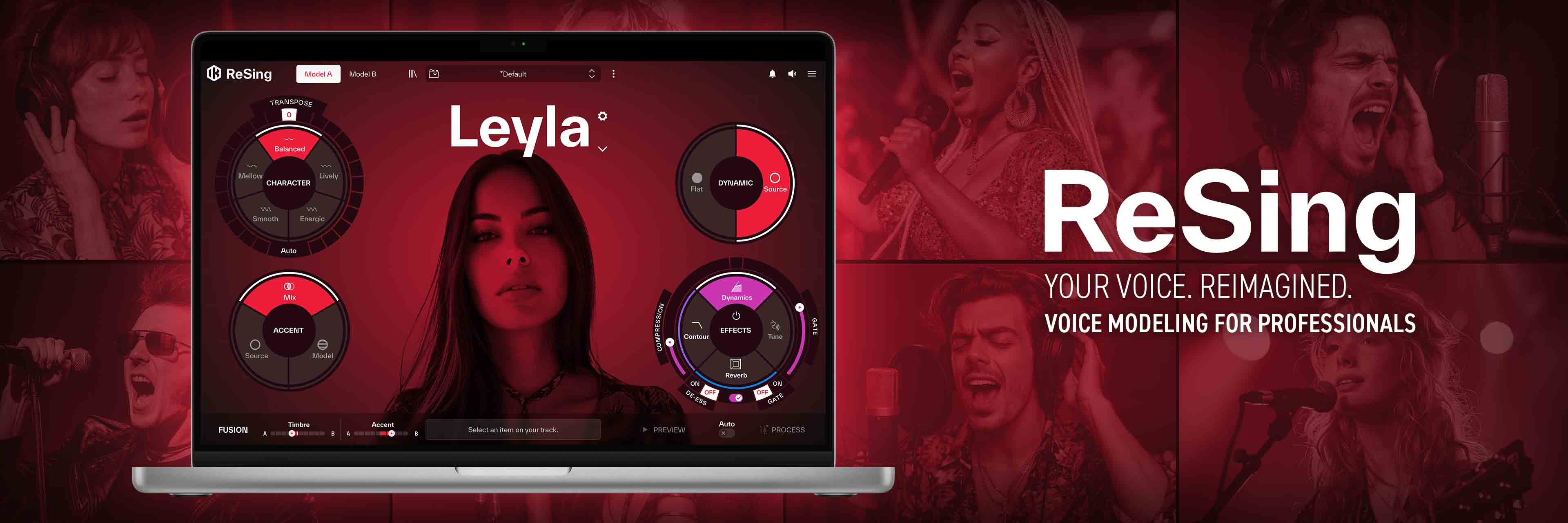
ReSing 的主面板集中呈现声音模型的主要设置,包括模型选择、核心参数调节、效果处理以及音频载入与播放。在完成处理后,可立即对结果进行试听与进一步编辑。
主面板(Main Panel)概览

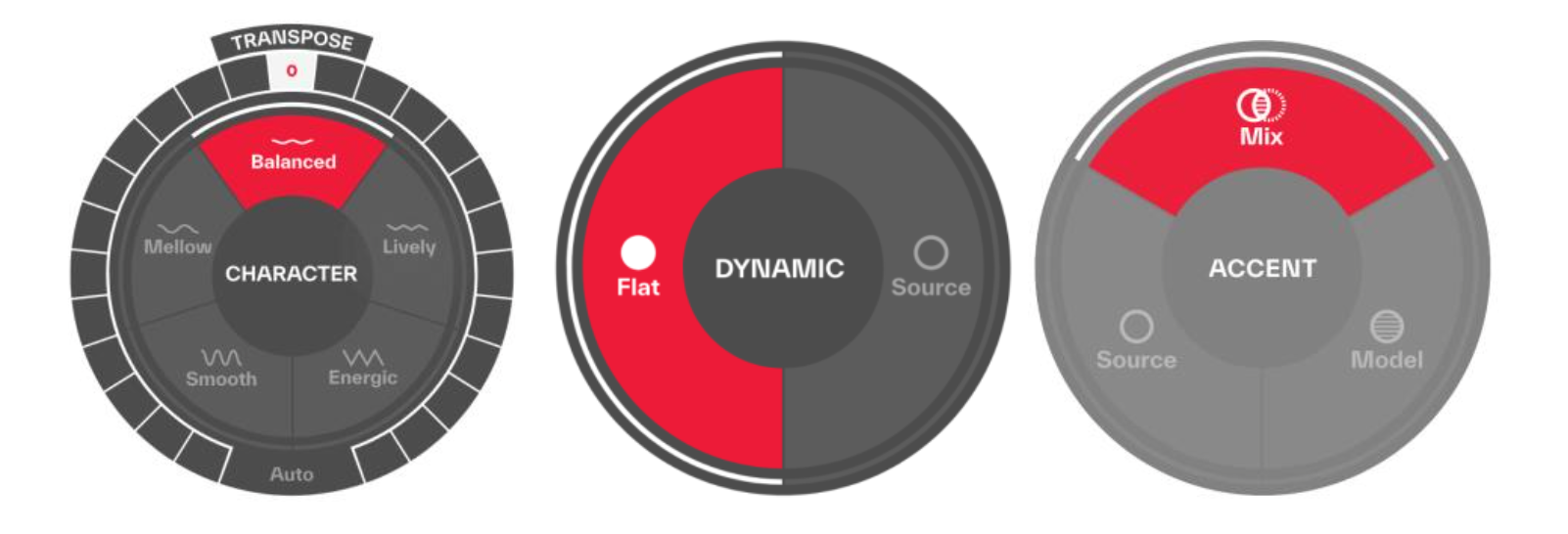
模型参数(Model Parameters)
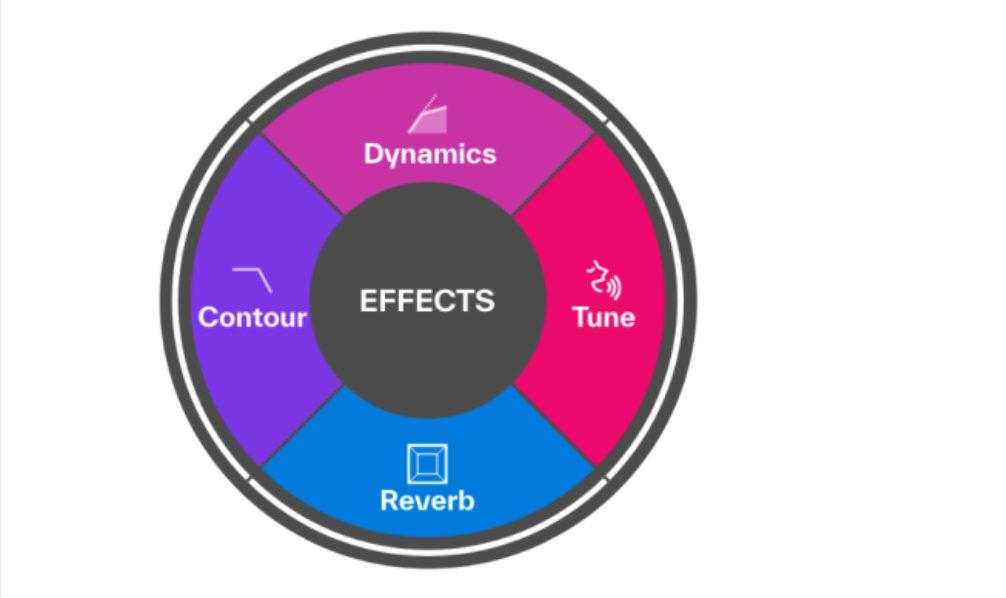
效果处理(Effects)
播放区与状态信息(Player / Notification)

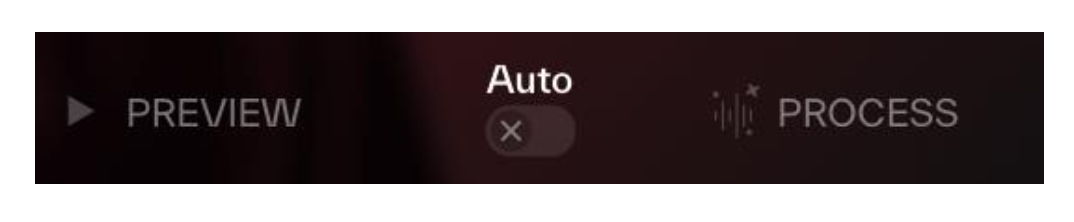
预览与处理(Preview and Process)
融合(Fusion)功能

常见问题解答
Q1:建模到底需要多少素材?
官方建议:15 分钟左右的干净录音素材。
干净 = 无背景音乐、无回声、语音自然不紧张。
GPU 强的话几十分钟即可训练一个模型;
CPU-only 可能要数天,这是正常现象。
Q2:ReSing 是本地处理还是在线处理?
完全本地处理,不上传云端。
你的音频不会被发出去。
这对于隐私和音频版权都很安全。
Q3:它能在哪些 DAW 里无缝工作?(ARA2)
官方目前支持的 ARA2 列表:
Cubase 12+
Logic Pro X 10.4+(Intel 版)
Studio One 4+
Nuendo 11+
Reaper 5.97+
其他 DAW 需要手动导入导出,但ARA支持正在扩展中。
Q4:模型能商用吗?能发给别人吗?
官方自带模型:都来自已签约授权的录音,允许用户用于作品中。
自己训练的模型:你要确保训练素材是你自己有权使用的。
模型分享/出售:要遵守 ReSing 的许可协议,避免侵犯声音所有者权利。
一句话:
你有版权,你就能用;你没版权,就别乱搞。
Q5:为什么有时候换出来的声音听起来“像机器人”?
常见原因:
原录音口型不清 / 背景噪音太重
模型风格与你的唱法差太多
参数调得太极端
某些句子发音太“奇怪”需要单独修
解决方法:
录音更清楚
Clarity 调高
Formant 调小幅度
逐句单独 fine-tune
越认真录制,效果越自然。
Bonus:ReSing创作进阶技巧

先分离清唱,再换音色(如果你只有伴奏文件)
多做几种模型的 A/B 对比
对难句进行单独渲染
输出后做一点点混响 + EQ,会更专业
一句话概括:
ReSing 是一款专业级的“声音换装器”+“私有 AI 声音工坊”。
它能让你用自己的表现,唱出别人音色;
也能让你创造一个“数字分身”帮你配音和唱歌。
对音乐人来说,它能把灵感 demo 秒变成“能听的版本”;
对视频创作者,它能让你的配音保持统一风格;
对声音爱好者,它让你第一次拥有真正属于自己的 AI 声音。